Agrupamiento Ejemplos de entrada - GIAA
Agrupamiento Ejemplos de entrada - GIAA
Agrupamiento Ejemplos de entrada - GIAA

Create successful ePaper yourself
Turn your PDF publications into a flip-book with our unique Google optimized e-Paper software.
<strong>Agrupamiento</strong><br />
<strong>Agrupamiento</strong><br />
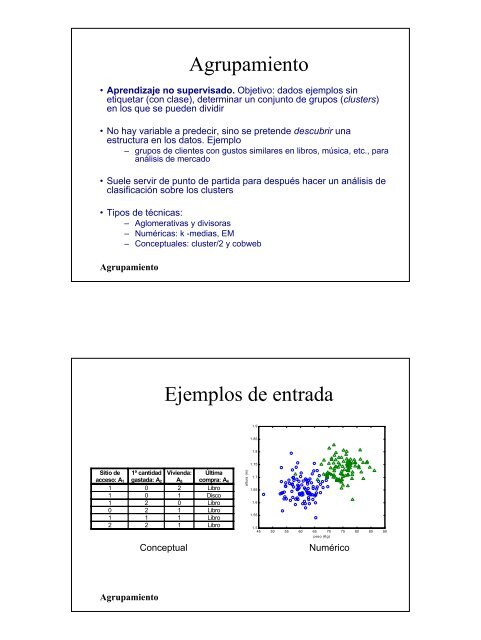
• Aprendizaje no supervisado. Objetivo: dados ejemplos sin<br />
etiquetar (con clase), <strong>de</strong>terminar un conjunto <strong>de</strong> grupos (clusters)<br />
en los que se pue<strong>de</strong>n dividir<br />
• No hay variable a pre<strong>de</strong>cir, sino se preten<strong>de</strong> <strong>de</strong>scubrir una<br />
estructura en los datos. Ejemplo<br />
– grupos <strong>de</strong> clientes con gustos similares en libros, música, etc., para<br />
análisis <strong>de</strong> mercado<br />
• Suele servir <strong>de</strong> punto <strong>de</strong> partida para <strong>de</strong>spués hacer un análisis <strong>de</strong><br />
clasificación sobre los clusters<br />
• Tipos <strong>de</strong> técnicas:<br />
– Aglomerativas y divisoras<br />
– Numéricas: k -medias, EM<br />
– Conceptuales: cluster/2 y cobweb<br />
<strong>Ejemplos</strong> <strong>de</strong> <strong>entrada</strong><br />
1.9<br />
1.85<br />
1.8<br />
Sitio <strong>de</strong><br />
acceso: A 1<br />
1ª cantidad<br />
gastada: A 2<br />
Vivienda:<br />
A 3<br />
Última<br />
compra: A 4<br />
1 0 2 Libro<br />
1 0 1 Disco<br />
1 2 0 Libro<br />
0 2 1 Libro<br />
1 1 1 Libro<br />
2 2 1 Libro<br />
Conceptual<br />
altura (m)<br />
1.75<br />
1.7<br />
1.65<br />
1.6<br />
1.55<br />
1.5<br />
45 50 55 60 65 70 75 80 85 90<br />
peso (Kg)<br />
Numérico<br />
<strong>Agrupamiento</strong>
Ejemplo <strong>de</strong> salidas<br />
• Conjunto <strong>de</strong> clases<br />
– Clase1: ejemplo4, ejemplo6<br />
– Clase2: ejemplo2, ejemplo3, ejemplo5<br />
– Clase3: ejemplo1<br />
• Jerarquía <strong>de</strong> clases<br />
Clase 1<br />
Clase 2<br />
Clase 3 Clase 4<br />
Clase 5 Clase 6<br />
<strong>Agrupamiento</strong><br />
Ej. Problema a resolver, k=3<br />
5<br />
4<br />
A2?<br />
3<br />
2<br />
1<br />
1 2 3<br />
<strong>Agrupamiento</strong><br />
4<br />
A1?
Solución 1<br />
5<br />
4<br />
A2?<br />
3<br />
2<br />
1<br />
1 2 3<br />
<strong>Agrupamiento</strong><br />
4<br />
A1?<br />
Solución 2<br />
5<br />
4<br />
A2?<br />
3<br />
2<br />
1<br />
1 2 3<br />
<strong>Agrupamiento</strong><br />
4<br />
A1?
<strong>Agrupamiento</strong> con k-medias<br />
Problema a resolver: distribuir los ejemplos en k conjuntos,<br />
minimizando las distancias entre elementos <strong>de</strong>ntro <strong>de</strong> cada grupo<br />
Algoritmo<br />
– Si se tienen que formar k clases, se eligen k ejemplos que<br />
actúan como semillas<br />
– Cada ejemplo se aña<strong>de</strong> a la clase mas similar<br />
– Cuando se termina, se calcula el centroi<strong>de</strong> <strong>de</strong> cada clase,<br />
que pasan a ser las nuevas semillas<br />
– Se repite hasta que se llega a un criterio <strong>de</strong> convergencia<br />
(p.e. Dos iteraciones no cambian las clasificaciones <strong>de</strong> los<br />
ejemplos)<br />
• Es un método <strong>de</strong> optimización local. Depen<strong>de</strong> <strong>de</strong> la elección <strong>de</strong> la<br />
semilla inicial<br />
– Pue<strong>de</strong> iterarse con varias semillas y seleccionar el mejor<br />
– Variantes para agrupamiento jerárquico<br />
<strong>Agrupamiento</strong><br />
Ejemplo <strong>de</strong> k-medias. Inicio<br />
A2?<br />
5<br />
4<br />
3<br />
Semilla 3<br />
2<br />
1<br />
Semilla 1<br />
Semilla 2<br />
<strong>Agrupamiento</strong><br />
1 2 3<br />
4<br />
A1?
Ejemplo <strong>de</strong> k-medias. Iteración 1<br />
5<br />
Centroi<strong>de</strong> 3<br />
4<br />
A2?<br />
3<br />
2<br />
1<br />
Centroi<strong>de</strong> 1<br />
1 2 3<br />
<strong>Agrupamiento</strong><br />
Centroi<strong>de</strong> 2<br />
4<br />
A1?<br />
Ejemplo <strong>de</strong> k-medias. Iteración 2<br />
5<br />
Centroi<strong>de</strong> 3<br />
4<br />
A2?<br />
3<br />
2<br />
1<br />
Centroi<strong>de</strong> 1<br />
1 2 3<br />
<strong>Agrupamiento</strong><br />
Centroi<strong>de</strong> 2<br />
4<br />
A1?
Ejemplo <strong>de</strong> k-medias. Iteración 3<br />
5<br />
Centroi<strong>de</strong> 3<br />
4<br />
A2?<br />
3<br />
2<br />
1<br />
Centroi<strong>de</strong> 1<br />
1 2 3<br />
<strong>Agrupamiento</strong><br />
Centroi<strong>de</strong> 2<br />
4<br />
A1?<br />
Ej2. Problema a resolver, k=2<br />
5<br />
4<br />
A2?<br />
3<br />
2<br />
1<br />
1 2 3<br />
<strong>Agrupamiento</strong><br />
4<br />
A1?
Ej2. Inicio<br />
A2?<br />
5<br />
4<br />
3<br />
Semilla 1 Semilla 2<br />
2<br />
1<br />
1 2 3<br />
<strong>Agrupamiento</strong><br />
4<br />
A1?<br />
Ej2. Situación estable<br />
5<br />
4<br />
A2?<br />
3<br />
2<br />
1<br />
1 2 3<br />
<strong>Agrupamiento</strong><br />
4<br />
A1?
Ej2. Inicio<br />
A2?<br />
5<br />
4<br />
3<br />
Semilla 1<br />
2<br />
Semilla 2<br />
1<br />
<strong>Agrupamiento</strong><br />
1 2 3<br />
4<br />
A1?<br />
Ej2. Situación estable<br />
5<br />
4<br />
A2?<br />
3<br />
2<br />
1<br />
1 2 3<br />
<strong>Agrupamiento</strong><br />
4<br />
A1?
Ej2. Inicio<br />
5<br />
4<br />
Semilla 2<br />
A2?<br />
3<br />
2<br />
1<br />
Semilla 1<br />
<strong>Agrupamiento</strong><br />
1 2 3<br />
4<br />
A1?<br />
Ej2. Situación estable<br />
5<br />
4<br />
A2?<br />
3<br />
2<br />
1<br />
1 2 3<br />
<strong>Agrupamiento</strong><br />
4<br />
A1?
Cálculo <strong>de</strong> la distancia<br />
• Dados dos ejemplos X i , X j , con atributos x il , x jl , l=1,…, F<br />
• La similitud pue<strong>de</strong> estimarse con el inverso <strong>de</strong> la distancia<br />
• Problemas:<br />
– atributos con diferentes rangos o importancias:<br />
• normalizar valores<br />
– atributos nominales:<br />
<strong>Agrupamiento</strong><br />
F<br />
d(X =<br />
2<br />
i , X j)<br />
∑ (xil−x<br />
jl)<br />
l=<br />
1<br />
• distancia estadística (Mahalanobis):<br />
F<br />
2<br />
ρ ρ (xil−x<br />
jl)<br />
d(Xi,<br />
X j)<br />
= ∑ ,<br />
2<br />
l=<br />
1 σ<br />
l<br />
⎪⎧<br />
1,<br />
d(xil,<br />
x jl)<br />
= ⎨<br />
⎪⎩<br />
0,<br />
si xil<br />
≠ x jl<br />
si xil<br />
= x jl<br />
d(Xi,<br />
X j)<br />
=<br />
ρ ρ t<br />
( )<br />
1 ρ ρ<br />
X − X S<br />
−<br />
( X − X )<br />
i<br />
j<br />
i<br />
j<br />
<strong>Agrupamiento</strong> conceptual<br />
• Problema <strong>de</strong> los enfoques numéricos: distancia cuando atributos son no<br />
numéricos<br />
• En el agrupamiento conceptual una partición <strong>de</strong> los datos es buena si<br />
cada clase tiene una buena interpretación conceptual (mo<strong>de</strong>lo cognitivo<br />
<strong>de</strong> jerarquías)<br />
• Hay dos tareas (Fisher y Langley, 85 y 86):<br />
– agrupamiento: <strong>de</strong>terminación <strong>de</strong> subconjuntos útiles <strong>de</strong> un<br />
conjunto <strong>de</strong> datos (métodos numéricos)<br />
– caracterización: <strong>de</strong>terminación <strong>de</strong> un concepto por cada<br />
subconjunto <strong>de</strong>scrito extensionalmente (métodos conceptuales)<br />
• COBWEB es un algoritmo incremental <strong>de</strong> agrupamiento que forma un<br />
árbol añadiendo ejemplos uno por uno<br />
– La actualización con un nuevo ejemplo pue<strong>de</strong> suponer ubicarlo en<br />
su hoja más a<strong>de</strong>cuada, o bien una re-estructuración con la nueva<br />
información<br />
<strong>Agrupamiento</strong>
Ejemplo<br />
e 4 ?<br />
Clase 1<br />
• Varias alternativas <strong>de</strong> particiones:<br />
– P 1 =[{e 1 , e 2 },{e 3 , e 4 }]<br />
– P 2 =[{e 1 , e 2 , e 3 ,}, {e 4 }]<br />
• Calidad <strong>de</strong> cada partición?<br />
• Creación <strong>de</strong> una nueva clase?: [{e 1 , e 2 },{e 3 }, {e 4 }]<br />
<strong>Agrupamiento</strong><br />
Clase 2 Clase 3<br />
e 1 , e 2 e 3<br />
Creación <strong>de</strong>l árbol<br />
• COBWEB crea incrementalmente un árbol cuyos nodos son<br />
conceptos probabilísticos<br />
• La clasificación consiste en <strong>de</strong>scen<strong>de</strong>r por las ramas cuyos nodos<br />
se equiparen mejor, basándose en los valores <strong>de</strong> varios atributos<br />
al mismo tiempo<br />
• Realiza búsqueda en escalada en el espacio <strong>de</strong> árboles<br />
probabilísticos <strong>de</strong> clasificación<br />
• Operadores:<br />
– Clasificar una instancia en una clase (nodo)<br />
– Crear una nueva clase<br />
– Combinar dos clases en una<br />
– Separar una clase en varias<br />
– Promocionar un nodo<br />
• En cada nodo se guarda:<br />
– Número <strong>de</strong> instancias por <strong>de</strong>bajo<br />
– En cada atributo Aj, valor l, número <strong>de</strong> ejemplos con A j<br />
= V jl<br />
<strong>Agrupamiento</strong>
<strong>Agrupamiento</strong><br />
Operadores <strong>de</strong> agrupamiento<br />
• Clasificar una instancia:<br />
– Se introduce la instancia en cada una <strong>de</strong> las clases<br />
sucesoras <strong>de</strong> la actual y se evalúan las distintas categorías<br />
– Si el mejor es un nodo hoja, se introduce en el. Si no, se<br />
llama recursivamente al algoritmo con él<br />
• Crear una clase:<br />
– Se comparan las calida<strong>de</strong>s <strong>de</strong>:<br />
• la partición creada por añadir la instancia a la mejor clase<br />
• la partición resultante <strong>de</strong> crear una nueva clase para esa<br />
instancia sola<br />
– En caso <strong>de</strong> ser mejor que este s ola, se crea un nuevo<br />
sucesor <strong>de</strong> la clase actual<br />
Operadores <strong>de</strong> agrupamiento<br />
• Los dos operadores anteriores <strong>de</strong>pen<strong>de</strong>n mucho <strong>de</strong>l or<strong>de</strong>n <strong>de</strong> los<br />
ejemplos.<br />
– Un análisis completo <strong>de</strong> reestructuración no es viable<br />
– Se incorporan dos operadores básicos para compensar:<br />
• Combinar dos nodos: Cuando se intenta clasificar una instancia<br />
en un nivel, se intentan mezclar las dos mejores clases y se<br />
evalúan las categorías <strong>de</strong> si están mejor solas o juntas en una<br />
misma categoría<br />
e?<br />
A<br />
B<br />
<strong>Agrupamiento</strong><br />
A<br />
B
Operadores <strong>de</strong> agrupamiento<br />
• Separar dos nodos: Cuando se intenta introducir una instancia<br />
en una clase que tenga sucesores, se estudia si se pue<strong>de</strong>n subir<br />
los sucesores al mismo nivel que la clase<br />
e?<br />
e?<br />
A<br />
B<br />
• Promocionar un nodo: El mismo operador anterior, pero<br />
individualizado para un solo nodo<br />
A<br />
B<br />
e?<br />
e?<br />
A<br />
<strong>Agrupamiento</strong><br />
B<br />
A<br />
B<br />
<strong>Agrupamiento</strong><br />
Heurística <strong>de</strong> búsqueda<br />
• Define el nivel básico (aspecto cognitivo)<br />
• Ayuda a consi<strong>de</strong>rar al mismo tiempo la similitud intra-clase y la disimilitud<br />
inter-clases<br />
– Intra-clase (p( A i<br />
= V ij<br />
lC k<br />
)): cuanto mas gran<strong>de</strong>, más ejemplos en la<br />
clase comparten el mismo valor (clases homogéneas)<br />
– Inter-clases (p( C k<br />
|A i<br />
=V ij<br />
)): cuanto mas gran<strong>de</strong>, menos ejemplos <strong>de</strong><br />
distintas clases comparten el mismo valor (separación entre clases)<br />
• Calidad <strong>de</strong> una partición {C 1<br />
, C 2<br />
,...,C M<br />
}, C k<br />
mutuamente excluyentes, es<br />
un compromiso entre las dos:<br />
M<br />
∑∑∑ p(Ai = Vij)p(Ck<br />
| Ai<br />
= Vij)p(Ai<br />
= Vij<br />
| Ck<br />
)<br />
k=<br />
1 i j<br />
don<strong>de</strong> p(A i<br />
=V ij<br />
) prefiere valores más frecuentes
<strong>Agrupamiento</strong><br />
Utilidad <strong>de</strong> una categoría<br />
• Como, según Bayes,<br />
p (A i =V ij )p(C k |A i =V ij ) = p(C k )p(A i =V ij |C k )<br />
sustituyendo: M<br />
2<br />
∑ p(Ck ) ∑∑ p(Ai<br />
= Vij<br />
| Ck<br />
)<br />
k=<br />
1 i j<br />
2<br />
don<strong>de</strong> ∑∑ i jp(Ai = Vij<br />
| Ck<br />
) es el numero esperado <strong>de</strong><br />
valores <strong>de</strong> atributos que se pue<strong>de</strong>n pre<strong>de</strong>cir correctamente para<br />
un miembro cualquiera <strong>de</strong> C k<br />
• La utilidad <strong>de</strong> una categoría C k es la mejora con respecto a no<br />
tener información <strong>de</strong> la partición:<br />
⎡<br />
2<br />
p(C k ) ⎢∑∑ p(A i = Vij<br />
| C k ) − ∑∑ p(A i = Vij<br />
)<br />
⎣ i j<br />
i j<br />
2<br />
⎤<br />
⎥<br />
⎦<br />
<strong>Agrupamiento</strong><br />
Utilidad <strong>de</strong> una partición<br />
• La utilidad <strong>de</strong> una partición P={C 1 , C 2 , ..., C M } es:<br />
CU(P) =<br />
1<br />
M<br />
M<br />
∑<br />
⎡<br />
2<br />
p(Ck ) ⎢∑∑ p(Ai<br />
= Vij<br />
| Ck<br />
) − ∑∑ p(Ai<br />
= Vij)<br />
⎣ i j<br />
k=<br />
1<br />
i j<br />
• Para evitar sobrea<strong>de</strong>cuamiento (un grupo por ejemplo)<br />
– Factor 1/M:<br />
– Factor <strong>de</strong> poda (cut-off): mejora en utilidad por una subdivisión<br />
• Si el valor V ij <strong>de</strong> un atributo A i es in<strong>de</strong>pendiente <strong>de</strong> la pertenencia<br />
a la clase C k :<br />
p(A i =V ij |C k ) = p(A i =V ij )<br />
para ese valor la utilidad <strong>de</strong> la partición es nula<br />
• Si lo anterior es cierto para todos los valores l, el atributo A j es<br />
irrelevante<br />
2<br />
⎥<br />
⎦<br />
⎤
<strong>Agrupamiento</strong><br />
Atributos numéricos<br />
• Los atributos numéricos se mo<strong>de</strong>lan con una distribución normal<br />
f (a ) =<br />
i<br />
1 ⎡ 1 (a − µ<br />
⎢−<br />
i )<br />
exp<br />
2πσ<br />
2<br />
⎣ 2 σ<br />
• Equivalente a suma cuadrática <strong>de</strong> probabilida<strong>de</strong>s:<br />
+∞<br />
2 2<br />
1<br />
∑ jp(Ai<br />
= Vij<br />
| Ck<br />
) ↔ ∫ f (ai)dai<br />
=<br />
−∞<br />
2 πσi<br />
1 M 1 ⎛ 1 1 ⎞<br />
CU (C 1 , C 2 ,..., C M ) = ∑ p (C k ) ∑ ⎜ − ⎟<br />
M k = 1 2 π i ⎝ σ ik σ i ⎠<br />
⎤<br />
⎥<br />
⎦<br />
• Un grupo con un ejemplo tendría utilidad infinita:<br />
– Agu<strong>de</strong>za (acurity): mínima varianza en un grupo<br />
2<br />
Algoritmo <strong>de</strong> agrupamiento<br />
Nodo COBWEB (Instancia,Nodo) {<br />
Actualizar los contadores <strong>de</strong> Nodo;<br />
Si Nodo es hoja<br />
Entonces IncluirInstancia (Instancia,Nodo);<br />
Devolver Nodo<br />
Si no MejorNodo= MejorClase (Instancia,Nodo);<br />
Si es apropiado crear una nueva clase<br />
Entonces Nuevo-nodo:= CrearNodo (Instancia,Nodo);<br />
Devolver Nuevo-nodo<br />
Si es apropiado combinar dos nodos<br />
Entonces Nuevo-nodo:= CombinarNodos (Instancia,Nodo);<br />
Devolver COBWEB (Instancia,Nuevo-nodo)<br />
Si es apropiado separar dos nodos<br />
Entonces Nuevo-nodo:= SepararNodos (Instancia,Nodo);<br />
Devolver COBWEB (Instancia,Nodo)<br />
Si es apropiado promocionar un nodo<br />
Entonces Nuevo-nodo:= PromocionarNodo (Instancia,Nodo);<br />
Devolver COBWEB (Instancia,Nodo)<br />
Si no, Devolver COBWEB (Instancia,MejorNodo) }<br />
<strong>Agrupamiento</strong>
<strong>Agrupamiento</strong> probabilístico (EM)<br />
• El agrupamiento con categorías presenta algunos problemas<br />
– Depen<strong>de</strong>ncia <strong>de</strong>l or<strong>de</strong>n<br />
– Ten<strong>de</strong>ncia al sobreajuste<br />
• Esta aproximación evita las divisiones prematuras, asignando<br />
parámetros a un mo<strong>de</strong>lo <strong>de</strong> mezcla <strong>de</strong> distribuciones<br />
• Mezcla <strong>de</strong> k distribuciones <strong>de</strong> probabilidad, representando los k<br />
0.06<br />
clusters.<br />
0.05<br />
µ1=18; µ2=40;<br />
0.04<br />
σ1=8; σ2=6;<br />
0.03<br />
p1=0.6<br />
0.02<br />
p2=0.4<br />
p(a)<br />
0.01<br />
0<br />
0 10 20 30 40 50 60<br />
a<br />
• Se <strong>de</strong>termina la probabilidad <strong>de</strong> que cada instancia proceda <strong>de</strong><br />
cada grupo<br />
<strong>Agrupamiento</strong><br />
Algoritmo EM<br />
• Se <strong>de</strong>termina el número <strong>de</strong> grupos a ajustar: k<br />
• En cada grupo, parámetros <strong>de</strong> las distribuciones <strong>de</strong> cada atributo<br />
p i<br />
, µ i<br />
, σ i<br />
i=1...k<br />
Ej.: 2 grupos (A, B) y un atributo: 5 parámetros<br />
• En cada iteración hay dos etapas:<br />
• “Expectation”: se calculan las probabilida<strong>de</strong>s <strong>de</strong> cada ejemplo en<br />
cada uno <strong>de</strong> los grupos<br />
⎡<br />
2<br />
f (x | A)p<br />
− µ ⎤<br />
= A 1 1 (x<br />
= ⎢−<br />
A )<br />
Pr(A | x)<br />
; f (x | A) exp<br />
⎥<br />
f (x)<br />
2πσ<br />
2<br />
A ⎣ 2 σA<br />
⎦<br />
• “Maximization”: se calculan los parámetros <strong>de</strong> las distribuciones<br />
que maximicen la verosimilitud <strong>de</strong> las distribuciones<br />
wi<br />
= Pr(A | xi);<br />
w1x1<br />
+ ...w x<br />
µ<br />
n n<br />
A =<br />
;<br />
w1<br />
+ ...w n<br />
<strong>Agrupamiento</strong><br />
2<br />
2 w1(x1<br />
− µ A ) + ...w n (xn<br />
− µ A )<br />
σA<br />
=<br />
;<br />
w1<br />
+ ...w n
Algoritmo EM<br />
• Condición <strong>de</strong> parada:<br />
– se estima la verosimilitud sobre todo el conjunto <strong>de</strong> instancias:<br />
n<br />
∏ [ f (xi<br />
| A)pA<br />
+ f (xi<br />
| B) pB]<br />
i=<br />
1<br />
– se para cuando la mejora en sucesivas iteraciones está <strong>de</strong>bajo <strong>de</strong> ε<br />
• Extensión:<br />
– <strong>Ejemplos</strong> con varios atributos y clases<br />
• Pue<strong>de</strong> asumirse in<strong>de</strong>pen<strong>de</strong>ncia (Naive Bayes) o estimar<br />
covarianzas (problema <strong>de</strong> sobreajuste)<br />
– Atributos nominales:<br />
• Se <strong>de</strong>terminan las probabilida<strong>de</strong>s condicionales para cada<br />
valor<br />
– No asegura mínimo global: varias iteraciones<br />
– Se pue<strong>de</strong>n estimar el número <strong>de</strong> grupos automáticamente,<br />
mediante validación cruzada<br />
<strong>Agrupamiento</strong><br />
Ejemplo<br />
• 300 datos proce<strong>de</strong>ntes <strong>de</strong> dos distribuciones (no conocidas)<br />
– pA=0.8; µA=18; σA=8; pB=0.2; µB=50; σB=6;<br />
• Inicialización:<br />
– pA=pB=0.5; σA=σΒ=10.0;µA,µB en dos ejemplos al azar<br />
0.045<br />
0.04<br />
0.035<br />
0.03<br />
0.025<br />
0.02<br />
0.015<br />
0.01<br />
0.005<br />
0<br />
-20 -10 0 10 20 30 40 50 60 70<br />
<strong>Agrupamiento</strong>
Ejemplo<br />
0.045<br />
0.04<br />
0.035<br />
0.03<br />
0.025<br />
0.02<br />
Iteración 2<br />
pA = 0.57; mA =30.68;<br />
sA =15.0299<br />
pB = 0.42; mB =14.61<br />
sB = 7.23<br />
0.045<br />
0.04<br />
0.035<br />
0.03<br />
0.025<br />
0.02<br />
Iteración 5<br />
pA = 0.45; mA =33.42;<br />
sA =16.38<br />
pB = 0.55; mB =16.05<br />
sB = 6.1<br />
0.015<br />
0.015<br />
0.01<br />
0.01<br />
0.005<br />
0.005<br />
0<br />
-20 -10 0 10 20 30 40 50 60 70<br />
0<br />
-20 -10 0 10 20 30 40 50 60 70<br />
0.045<br />
0.045<br />
0.04<br />
0.035<br />
0.03<br />
0.025<br />
0.02<br />
0.015<br />
Iteración 15<br />
pA = 0.33; mA =39.0;<br />
sA =14.7<br />
pB = 0.67; mB =16.37<br />
sB = 6.75<br />
0.04<br />
0.035<br />
0.03<br />
0.025<br />
0.02<br />
0.015<br />
Iteración 30<br />
pA = 0.2; mA =49.2;<br />
sA =7.1<br />
pB = 0.8; mB =17.54<br />
sB = 7.54<br />
0.01<br />
0.01<br />
0.005<br />
0.005<br />
0<br />
-20 -10 0 10 20 30 40 50 60 70<br />
0<br />
-20 -10 0 10 20 30 40 50 60 70<br />
<strong>Agrupamiento</strong>