
Ask any Linux user, and you’ll find that many prefer to type out commands in the terminal rather than using the GUI. This is because of the power and versatility of Linux commands that can carry out complicated tasks without going through multiple windows.
The Linux pipe command is a handy command that allows you to connect two commands to carry out multiple actions with just a single line.
This article introduces the pipe command and then goes into the details of how you can use this command to get everyday tasks done in minutes.
Let’s start with the fundamentals.
Table Of Content
-
-
-
-
- What is the Pipe Command in Linux?
- Pipe Command Standard Usage
- Why Should You Use The Pipe Command?
- Simplify Complex Operations
- Improved Efficiency
- Facilitate Task Automation
- Enhanced Readability
- How Can You Use The Pipe Command For Everyday Tasks
- Utilize Pipes To Order The List
- Removing Duplicates From The List
- Display Data That Matches Your Required Range
- Using Pipe With More
- Count The Number Of Files
- Identify A Process
- Get the List of All the Subdirectories in A Directory
- Get Specific Data From A File
- Conclusion
-
-
-
What is the Pipe Command in Linux?
In practical terms, the Pipe command takes the output of a command and pushes it as the input for another command. This greatly facilitates stringing commands to execute multi-step tasks.
If you don’t use the Pipe command, you have to work with intermediate files to save the output of the first command. Then you would have to use the file as input for the second command. These steps introduce the chances of mistakes that result in delays.
The Linux Pipe command eliminates all this by connecting multiple commands into a single multi-stage command.
Linux Pipe Command Standard Usage
Here is the standard syntax of the Pipe command:
command1 | command2
The command on the right-hand side of the pipe symbol (|) is executed after the command on the left-hand side of the pipe symbol has finished running, and the standard output of the first command is linked to the input of the second command. As a result, the commands are linked together, with the second command accepting and processing the first command’s output.
Why Should You Use The Pipe Command?
The Linux Pipe command is very often used in shell scripts and standalone terminal commands because it can cascade other Linux commands and bring a degree of automation to everyday tasks.
Here are four reasons why you should use Pipe more often:
Simplify Complex Operations
Connecting multiple commands with pipes allows you to perform complex operations with relatively straightforward syntax. This can make your command line scripts and workflows easier to read, understand, and, most importantly, duplicate.
Improved Efficiency
Pipes bring efficiency to your everyday tasks by directly plugging the output of one command into another command. Now you don’t have to deal with files and intermediate read and write steps. In addition, you’ll find pipes very efficient in moving data as parameters for commands.
Facilitate Task Automation
Pipes are a great way of automating complex operations by connecting multiple commands in a shell script. This can make it easier to repeat and automate your workflows. You can even pipe the output of a script as input to another script.
Enhanced Readability
Pipes allow you to break down complex operations into smaller, more manageable steps, making it easier to understand what each step does and how it contributes to the overall operation.
How Can You Use The Pipe Command For Everyday Tasks
The pipe is a very interesting command because you can use it with almost every Linux command. That means you can carry out multiple commands in a single line.
Here’re a few ways you can use pipes to facilitate and speed up your workflows.
Utilize Pipes To Order The List
The pipe’s many functions include filtering, sorting, and displaying a list’s text. Here is a description of one of the typical examples. Suppose you have a file named file1.txt that contains countries’ names. Let’s say the Country’s names are in a file called file1.txt. We can use the cat command to retrieve the contents of this file.
# cat file1.txt

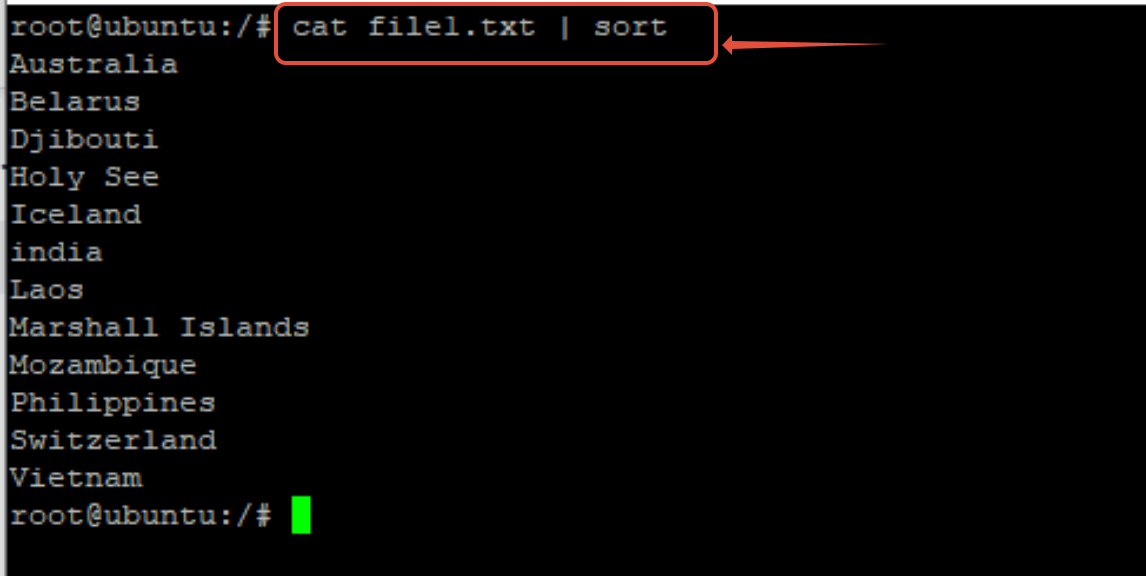
You’ll notice that the contents of the file are in no particular order. A common task is to sort this data. For this, we could use the sort command. However, we can pipe the output of the cat command into the sort command. You can see the names of the countries are now sorted in alphabetical order.
# cat file1.txt | sort
Removing Duplicates From The List
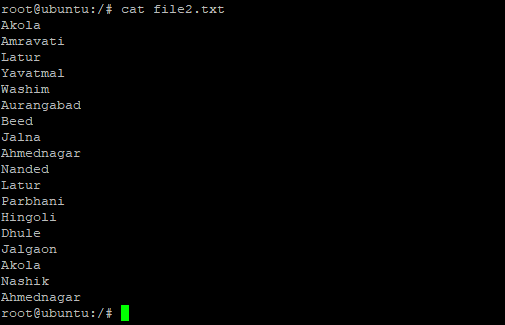
You might need to remove duplicate entries from the list and sort the output in alphabetical order. This requires piping three commands, cat for printing the list, sort for sorting the list, and uniq for removing duplicate entries.
# cat file2.txt | sort | uniq

As you can see, the items in the list are sorted and ordered with no duplicate entries. Here’s how the file looked before sorting and removal of duplicate entries.
Display Data That Matches Your Required Range
There are times when you don’t want all the data in a file. Rather, you just want a couple of entries.
Linux provides a handy head utility to get the beginning of the data in the file. You can specify a range for the head command so that it only fetches the data within the range.
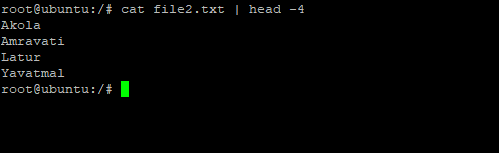
For instance, if we want just the top 4 entries of the file named file2.txt, we can pipe the output of the cat command into the head command. This will display just the top four entries.
# cat file2.txt | head -4
Using Pipe With More
You have seen the contents of directories quickly scroll on the screen without giving you a chance to read them. This often happens with the list command used to view the files in a directory.
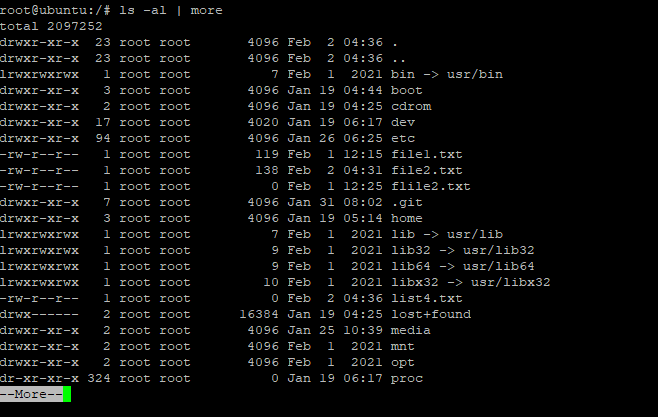
When you use Pipe with the ls command, the Pipe command serves as a container and uses the output of the ls -al command as input for the more command. As a result, you can easily view the lengthy output with ease.
# ls –al | more
Count The Number Of Files
A very common everyday task is to find out how many files there are. While you can use grep or cat commands, we have a faster solution that uses a Linux pipe to connect the ls command with the wc command.
$ ls | wc -l
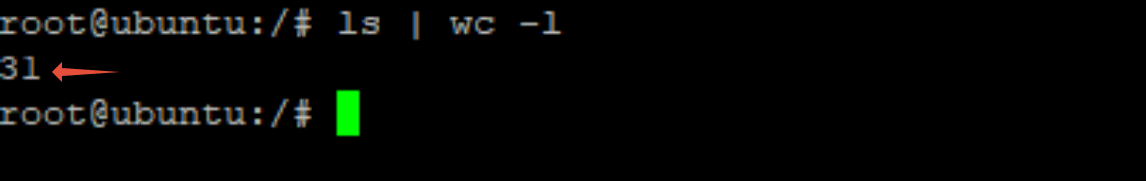
As you can see, the ls command gets the total files, while the wc command counts their number.
Identify A Process
Now, let’s try an advanced task that sysadmins often carry out in the course of a workday – getting the system process ids. This requires piping three commands:
# ps –ef | grep systemd | awk ‘{print $2}’

As you can see the piped output displays a list of system process id.
Get the List of All the Subdirectories in A Directory
One of the most common searches is finding out the number and details of the subdirectories contained within a directory.
This is a perfect task for the Linux Pipe command because it requires sending the output of the list command to the grep command. As an added complication, we want the grep command to filter the data and display entries starting with a ‘d’.
Here’s the piped command for this scenario:
# ls –al | grep ‘^d’

Get Specific Data From A File
There are instances where you want to extract data that match very specific criteria. The Linux Pipe command allows you to cascade multiple commands so that you get the data you want from the file.
To demonstrate the idea, suppose you want to get all words from a file that contains the letter a. For this, you can use this command:
# cat file2.txt | grep a

The outcomes show that the data was fetched in accordance with the criteria passed on to the grep command.
Now, if you need to get the list of words containing the letter s, and use the -i flag for case sensitivity. Here’s how the command will look:
$ cat file2.txt | grep –i s

Now, if you want to get the words that have the letter a followed by the letter s, use the command:
$ cat file1.txt | grep “a\+s”

Conclusion
The example shows how flexible the pipe command is in Linux. Even though it is relatively straightforward, it may answer a lot of complex questions. This command-line tool is simple to use and suitable for both Linux and UNIX operating systems.
