
Abstract
Acromegaly is a rare disease characterized by an excessive production of growth-hormone and insulin-like growth factor 1, typically resulting from a GH-secreting pituitary adenoma. This study was aimed at comparing and measuring accuracy of newly and previously developed coding algorithms for the identification of acromegaly using Italian claims databases. This study was conducted between January 2015 and December 2018, using data from the claims databases of Caserta Local Health Unit (LHU) and Sicily Region in Southern Italy. To detect acromegaly cases from the general target population, four algorithms were developed using combinations of diagnostic, surgical procedure and co-payment exemption codes, pharmacy claims and specialist’s visits. Algorithm accuracy was assessed by measuring the Youden Index, sensitivity, specificity, positive and negative predictive values. The percentage of positive cases for each algorithm ranged from 7.9 (95% CI 6.4–9.8) to 13.8 (95% CI 11.7–16.2) per 100,000 inhabitants in Caserta LHU and from 7.8 (95% CI 7.1–8.6) to 16.4 (95% CI 15.3–17.5) in Sicily Region. Sensitivity of the different algorithms ranged from 71.1% (95% CI 54.1–84.6%) to 84.2% (95% CI 68.8–94.0%), while specificity was always higher than 99.9%. The algorithm based on the presence of claims suggestive of acromegaly in ≥ 2 different databases (i.e., hospital discharge records, copayment exemptions registry, pharmacy claims and specialist visits registry) achieved the highest Youden Index (84.2) and the highest positive predictive value (34.8; 95% CI 28.6–41.6). We tested four algorithms to identify acromegaly cases using claims databases with high sensitivity and Youden Index. Despite identifying rare diseases using real-world data is challenging, this study showed that robust validity testing may yield the identification of accurate coding algorithms.
Similar content being viewed by others


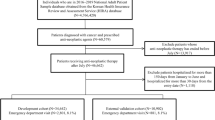
Introduction
Acromegaly is a chronic and progressive endocrine rare disease characterized by an excessive production of growth-hormone (GH) and insulin-like growth factor 1 (IGF-1), which typically results from a GH-secreting pituitary adenoma1. It has been estimated that acromegaly globally affects around 6 per 100,000 persons2. Epidemiological studies conducted in Italy reported a prevalence of acromegaly ranging from 6.9 to 9.7 cases per 100,000 persons3,4,5. The onset of acromegaly is usually slow and insidious, and the clinical conditions associated with it, such as arthritis, diabetes mellitus, hypertension, sleep apnea and metabolic dysfunction are common in general population6,7. As a result, acromegaly is often diagnosed late, thus influencing the long-term disease prognosis8 and leading to the development of complications and to increased mortality9. Disease prognosis is also conditioned by genetic and epigenetic variants10. The recommended diagnostic test for acromegaly consists in the assessment of age/sex normalized IGF-1 levels and GH levels during an oral glucose load in patients with the above-mentioned comorbidities. Nowadays, typical features of acromegaly can also be detected by multimedia tools11, useful systems for a modern diagnostic approach. Diagnoses based on laboratory tests should be confirmed thereafter by magnetic resonance imaging (MRI) (or computed tomography scan if MRI is contraindicated or unavailable) which are able to visualize adenoma size and appearance12. A multimodal therapeutic approach comprising neurosurgery, medical therapy and radiotherapy is often required to attain biochemical control and reduction of disease-related morbidity and mortality13. Surgery is generally recommended as the first-line therapy, while in patients with persistent disease following surgery medical treatment as adjuvant therapy is recommended14. There are three pharmacological classes currently available for acromegaly management, to be used as monotherapy or in combination, namely somatostatin analogues (i.e., octreotide, lanreotide and pasireotide), the GH receptor antagonist pegvisomant and dopamine agonists (e.g., cabergoline), which are off-label used15,16.
Although acromegaly is a rare disease, the clinical, economic and health-related quality of life burden is considerable due to the wide spectrum of comorbidities and the need for lifelong management17. Achieving biochemical control is associated with improvements in cost, quality of life, and mortality, albeit not to the level of the general population18.
Claims databases are widely used in pharmacoepidemiology to provide real-world evidence on disease burden, treatment patterns, healthcare resource utilization, benefit-risk profile of drugs and costs19. Italy is rich in electronic healthcare data at loco-regional and national level, and these data have been increasingly used in the last decade for research purposes. Large scale distributed database networks have also been set up in Italy, with the potential to substantially increase statistical power when studying rare diseases/outcomes20. However, the identification of rare diseases in claims databases remains challenging and requires validated coding algorithms.
Several epidemiologic studies applied different coding algorithms for acromegaly ascertainment in claims databases, but their accuracy has never been assessed, mostly due to the lack of a gold standard cohort with true positive cases.
The aim of this study was to newly develop and revise existing coding algorithms for the identification of acromegaly cases and to compare their accuracy in detecting such patients using claims databases from Caserta Local Health Unit (LHU) and Sicily Region, in Southern Italy.
Methods
Data sources
This Italian, retrospective, population-based study was conducted in the period January 2015–December 2018, using data extracted from the fully-anonymized administrative record linkage databases of Caserta Local Health Unit (LHU), with an average of 1,060,904 inhabitants. Moreover, data from the fully-anonymized administrative health databases of Sicily Region in the period January 2011–December 2018, with an average of 5,031,655 inhabitants, were used as a testing dataset to evaluate the performance of the proposed algorithms and to substantiate the estimates of acromegaly cases identified in Caserta LHU. Both databases contain demographic and medical data that is collected through services provided by the Italian National Health Service (NHS). They include information on demographics of residents in each catchment area, outpatient pharmacy claims, hospital discharges, exemptions from co-payment, referrals for outpatient diagnostic tests and specialist’s visits database. The content and context of such NHS claims databases have been described in detail elsewhere19. Claims databases from Caserta LHU also comprise the electronic therapeutic plans (ETP) database. In Italy, ETPs are directly filled by the specialists, who provide information on the exact brand name, number of dispensed packages, and indication for use. The dispensed drugs were coded using the Anatomical Therapeutic Clinical (ATC) classification system and the Italian Marketing Authorization Code (AIC), while comorbidities and indications of use were coded through the ninth revision of the International Classification of Diseases—Clinical Modification (ICD-9 CM).
Algorithm definition
To detect the presence of acromegaly in the target population, four different algorithms were proposed and developed based on a systematic review of published articles of acromegaly epidemiology using claims database-based algorithms2. Specifically, each algorithm was developed using a combination of acromegaly-related ICD-9 CM diagnostic codes (253.0), ICD-9 CM surgical procedure codes (07.6x and 92.3x), co-payment exemption codes (001 and 253.0), specialist visits, laboratory exams and pharmacy claims for somatostatin analogues (ATC: H01CB02, H01CB03, H01CB05) or pegvisomant (ATC: H01AX01). “Algorithm 1” was developed by Caputo et al. in 20184, “Algorithm 2” consisted of a revision of the “Algorithm 1”, which included further acromegaly-related codes, while the “Algorithm 3” and the “Algorithm 4” were developed through different combinations of the acromegaly-related codes used in published articles3,4,21,22,23. For each algorithm, as proposed by Caputo et al.4, pharmacy claims for drugs approved for acromegaly treatment were not taken into account if (i) patients had received less than three separate drug prescriptions for the treatment of acromegaly (occasional drug users) during the observation period; (ii) the medications were not long-acting release (LAR) formulations; (iii) patients taking octreotide or lanreotide had at least one hospitalization with a diagnosis that, as reported in the summary of product characteristics, is one of the indications for use of these drugs [i.e., malignant neoplasms (ICD-9 CM: 140–209, 230–239), liver disorders (ICD-9 CM: 570–573), gastrointestinal bleeding (ICD-9 CM: 578), esophageal varices (ICD-9 CM: 42), Cushing’s disease (ICD-9 CM: 255; 255.0)]; (iv) patients had a co-payment exemption code for Cushing’s disease (code: 032). Inclusion and exclusion criteria are reported in Table 1.
Gold standard cohort definition
In Caserta LHU, gold-standard cases were defined as subjects which had at least one registration in the ETP database with at least one ICD-9 CM code for acromegaly during the study period. Gold-standard non-cases were defined as all remaining subjects (i.e. registered in Caserta LHU with no ICD-9 CM codes for acromegaly in ETP database).
In Sicily Region, gold standard cases were defined as patients with a confirmed diagnosis of acromegaly in the Endocrinology Unit of the University Hospital of Messina, a province that lies in the Northeastern part of Sicily, during the study period. Data concerning non-cases were not available.
Statistical analysis
For each proposed algorithm, the accuracy was assessed by the sensitivity (SE) and specificity (SP) measures, along with their 95% confidence intervals (CIs) calculated using the exact Clopper–Pearson method for a binomial proportion. Moreover, the Youden Index (i.e. a summary statistic that balances both SE and SP)24 was computed and the algorithm that achieved the highest accuracy (i.e. Youden Index) was considered as the preferred one with respect to the others. Furthermore, the positive predictive value (PPV) and the negative predictive value (NPV) along with their 95% CIs, were also estimated to assess the algorithm’s accuracy. To visually assess the overlapping number of acromegaly cases detected by each coding algorithm with respect to different data sources, Venn diagrams were produced.
The four proposed algorithms were also applied to patients diagnosed with acromegaly in the Endocrinology Unit of the University Hospital of Messina through probabilistic record linkage and the proportion of true positives among these cases was compared with the SE achieved for each algorithm. In addition, to provide an estimate of the percentage of acromegaly cases in the Sicilian population, only the algorithm with the highest discriminatory power was performed in the administrative data of the Sicily Region (testing dataset).
Finally, for the algorithm with the highest Youden Index a network plot was produced to show the number of acromegalic patients identified in Caserta LHU and Sicily Region, respectively, to further substantiate the chronological occurrence of any acromegaly-specific code identified in each claims database. In particular, for each claims database, all the possible pathways by which the subjects were identified over time were represented. Each pathway is made of the chronological sequence by which every acromegaly-specific code occurred for each patient. This can be considered a proxy of the patient journey25.
All statistical analyses were performed using R Foundation for Statistical Computing (R Development Core Team 2008, Vienna, Austria, version: 4.0.3, packages: caret and PropCIs).
Ethics approval
Analyses were conducted in accordance with the ethical standards of the institutional and national research committee and with the 1964 Helsinki Declaration and its later amendments. This study was approved by the Ethics Committee of the Azienda Ospedaliera Universitaria Integrata of Verona (Protocol number 55986, 27th September 2021).
Consent to participate
Informed consent was obtained from all individual patients from the Endocrinology Unit of the University Hospital of Messina included in the study.
Results
In Caserta LHU, during the period 2015–2018, a total of 84, 92, 116 and 146 individuals were identified as having acromegaly according to “Algorithm 1”, “Algorithm 2”, “Algorithm 3” and “Algorithm 4”, respectively. The estimated percentage of positive cases in Caserta LHU (i.e., the number of detected cases over the total number of subjects) for each proposed algorithm ranged from 7.9 (95% CI 6.4–9.8) to 13.8 (95% CI 11.7–16.2) per 100,000 inhabitants (Table 2).
Seven overlapping cases were detected at all data sources by “Algorithm 1” and “Algorithm 2”, whereas 4 overlapping cases were detected in all data sources by “Algorithm 3” and “Algorithm 4”, respectively (Fig. 1).

Frequency distribution (Venn diagrams) of the number subjects identified by each proposed algorithm as having acromegaly, with respect to different data sources (i.e. databases of Caserta Local Health Unit and Sicily Region) during the study period.
Of the 1,060,904 subjects registered in Caserta LHU, 81,388 (7.7%) had least one registration in the ETP database. Among them, 38 individuals with at least one ICD-9 CM code for acromegaly (i.e. gold-standard cases) were identified, yielding an estimated prevalence of 3.6 (95% CI 2.6–4.9) cases per 100,000 inhabitants. The mean age of gold-standard cases was 54.5 ± 13.9 years and 20 (52.6%) of them were females. Concerning the 1,060,866 gold-standard non-cases, their mean age was 26.6 ± 20.7 years and 538,086 (50.7%) of them were females.
For each proposed algorithm, the number of true and false positive/negative counts as well as diagnostic measures are reported in Table 3.
SE ranged from 71.1% (95% CI 54.1–84.6%) for “Algorithm 1” to 84.2% (95% CI 68.8–94.0%) for “Algorithm 2” and “Algorithm 4”, while SP was higher than 99.9% for each proposed algorithm. The “Algorithm 2” achieved both the highest accuracy (i.e. Youden Index of 84.2%) and the highest accuracy (PPV of 34.8; 95% CI 28.6–41.6) and it was designated to be the preferred one.
The application of the coding algorithms on the claims databases of Sicily Region yielded a total of 394, 533, 768 and 824 acromegaly cases identified by “Algorithm 1”, “Algorithm 2”, “Algorithm 3” and “Algorithm 4”, respectively, with an estimated percentage of detected cases ranging from 7.8 (95% CI 7.1–8.6) to 16.4 (95% CI 15.3–17.5) per 100,000 inhabitants (Table 2). Only twenty-six and sixty-three overlapping cases were detected at all data sources by the “Algorithm 1” and “Algorithm 2”, respectively (Fig. 1). When assessed on the 76 (46 females and 30 males) confirmed acromegaly cases in the Endocrinology Unit of the University Hospital of Messina (Sicily), the percentage of true positives detected by “Algorithm 2” was 82.9% (95% CI 72.5–90.6), which was quite consistent with SE estimate in the Caserta LHU database. The mean age at diagnosis of these patients was 47.7 ± 17.4 years.
Patient journey maps showed that, for the majority of acromegalic patients identified by the “Algorithm 2” in Sicily Region, the first acromegaly-related code occurred in pharmacy claims database (188/533; 35.3%), while in Caserta LHU the first acromegaly-identifying code was mostly found in specialist’s visits database (58/92; 63.1%). The pathway of chronological occurrence of acromegaly-related codes in each claims database is shown in Fig. 2.

Network plots showing the chronological occurrence of each acromegalic-specific code included in the algorithm 2 in both Caserta Local Health Unit and Sicily Region. Each node represents each claims database (i.e., diagnostic codes, co-payment exemption codes, specialist’s visits and pharmacy claims). Edges define the chronological direction to follow to identify a specific pathway. In panel (a) the frequencies (defined with respect to the number of patients in the start node) of different criteria of acromegalic patients’ identification are reported along the edges. For instance, starting from the specialist visit records in Caserta Local Health Unit, 12 patients (20.7%) having both a first acromegaly diagnosis recorded in that dataset plus a later additional acromegaly-specific code in the co-payment exemptions database were counted. In panel (b) the corresponding median lag time (days) among different criteria of acromegalic patients’ identification is reported for each pathway identified. For instance, starting from the specialist visit records in Caserta Local Health Unit, for the 12 patients (20.7%), a median time of 567 necessary days to be identified also by a later additional acromegaly-specific code in the co-payment exemptions database was observed.
Discussion
To our knowledge, this is the first population-based study that assessed and compared the accuracy of different coding algorithms for the identification of patients with acromegaly using claims databases. Generating epidemiological evidence on rare diseases like acromegaly is crucial to evaluate their impact in terms of burden of disease and to identify unmet clinical needs.
All the four algorithms tested were able, to different extent, to identify true acromegalic patients in claims databases. Based on this, we found that both “Algorithm 2” and “Algorithm 4” provided the most reliable results matching the majority of true acromegalic patients (84.2%). In particular, the preferred “Algorithm 2” achieved the highest discriminatory accuracy, as shown by the Youden Index and PPV, and yielded an estimated prevalence comparable to the global one estimated in the meta-analysis2. Furthermore, as compared to the “Algorithm 4”, “Algorithm 2” yielded a better performance also according to principle of parsimony, since it required less acromegaly-identifying codes to be computed, achieving the same SE and higher SP. This algorithm was developed from the one proposed by Caputo et al.4 (“Algorithm 1”) by adding further codes for specific laboratory exams, such as the codes for somatotropic hormone measurement and IGF-1 levels measurement, and searching for acromegaly-specific co-payment exemptions also using ICD-9 codes. Indeed, in Italy, it is not uncommon that disease-specific co-payment exemptions are registered using the ICD-9 code rather than the specific exemption code. As compared to “Algorithm 1”, the addition of these codes led to considerable improvements in their accuracy.
The estimated percentages of positive acromegaly cases identified using both Caserta LHU and Sicily Region claims databases were slightly higher than the global prevalence estimated in our meta-analysis of observational studies [5.9 (95% CI 4.4–7.9) cases per 100,000 persons]2, but they were comparable to those reported in the Italian epidemiological studies, conducted by Gatto et al.3 and Caputo et al.4. This corroborates the fact that prevalence estimates based on the proposed algorithms are consistent when applied to different databases of different Italian geographical areas.
One of the main obstacles in using real-world data sources, especially for rare diseases, is related to disease coding and to the availability of specific diagnostic codes. In many cases, rare diseases do not have specific codes (e.g. muscular dystrophies) nor co-payment exemption codes20. However, as compared to other rare diseases, acromegaly diagnostic (ICD-9 CM: 253.0) and co-payment exemption (001) codes are rather specific, even if they also refer to gigantism, a clinical condition due to GH overproduction during childhood and adolescence, specifically. Therefore, such codes are reliable enough to identify acromegaly in claims databases. This also holds true for the drugs used for the management of acromegalic patients. The GH receptor antagonist pegvisomant is exclusively approved for the treatment of acromegaly in patients who have had an inadequate response to surgery and/or radiation therapy and/or other medical therapies; although somatostatin analogues are also approved for indications other than acromegaly, they are reliable proxies of acromegaly, especially when used in combination with other acromegaly-related codes.
Patient journey maps showed that most of the cases were primarily identified through pharmacy claims and specialists’ visit. Accordingly, the frequency of those healthcare services is in general much higher than hospitalizations, surgical procedures and exemption codes and, as compared to other services, are more likely to be more accurately identified in claims databases.
One of the main strengths of this study is that it is a large-scale population-based study, for a total of more than 6,000,000 patients from both Caserta LHU and Sicily Region. This is especially relevant for research in the field of rare diseases, where the number of affected patients is very small. However, some limitations warrant caution. Considering that the database used was claims-based, this study presents some limitations associated to this kind of data sources, such as potential misclassification due to potentially inconsistent and inaccurate coding practice. Moreover, since claims data are primarily collected for administrative purposes (e.g., reimbursement), the proposed coding algorithms may yield different performances in populations with different administrative practices and coding patterns. Finally, given that complete remission from the disease is achieved in around 50% of surgically-treated patients26,27,28,29,30 and that medical therapy is mainly indicated in those patients who failed to achieve remission after surgery, the extraction of the gold standard cohort from the ETP database may not be fully representative of acromegaly cases. Nevertheless, this has unlikely affected the comparison of the accuracy of different coding algorithms for acromegaly identification.
Conclusions
In this study, we have developed and tested four algorithms for the identification of acromegaly using claims databases from Caserta LHU and Sicily Region, achieving highly consistent diagnostic accuracy measures. Despite identifying a rare disease such as acromegaly using real-world data is challenging, this study showed that robust validity testing may yield the identification of accurate coding algorithms.
Data availability
The individual patient-level dataset generated and/or analyzed during the current study is not publicly available due to the agreement with data provider, but aggregated data can be shared from the corresponding author on reasonable request.
References
Colao, A. et al. Acromegaly. Nat. Rev. Dis. Primers 5(1), 20 (2019).
Crisafulli, S. et al. Global epidemiology of acromegaly: A systematic review and meta-analysis. Eur. J. Endocrinol. 185(2), 251–263 (2021).
Gatto, F. et al. Epidemiology of acromegaly in Italy: Analysis from a large longitudinal primary care database. Endocrine 61, 533–541 (2018).
Caputo, M. et al. Use of administrative health databases to estimate incidence and prevalence of acromegaly in Piedmont Region, Italy. J. Endocrinol. Investig. 42(4), 397–402 (2019).
Cannavò, S. et al. Increased prevalence of acromegaly in a highly polluted area. Eur. J. Endocrinol. 163(4), 509–513 (2010).
Fleseriu, M. et al. Prevalence of comorbidities and concomitant medication use in acromegaly: Analysis of real-world data from the United States. Pituitary 25(2), 296–307 (2022).
Ferraù, F., Albani, A., Ciresi, A., Giordano, C. & Cannavò, S. Diabetes secondary to acromegaly: Physiopathology, clinical features and effects of treatment. Front. Endocrinol. (Lausanne) 9, 358 (2018).
Lavrentaki, A., Paluzzi, A., Wass, J. A. & Karavitaki, N. Epidemiology of acromegaly: Review of population studies. Pituitary 20(1), 4–9 (2017).
Pivonello, R. et al. Complications of acromegaly: Cardiovascular, respiratory and metabolic comorbidities. Pituitary 20(1), 46–62 (2017).
Colao, A., Ferone, D., Marzullo, P. & Lombardi, G. Systemic complications of acromegaly: Epidemiology, pathogenesis, and management. Endocr. Rev. 25(1), 102–152 (2004).
Prencipe, N. et al. ACROSCORE: A new and simple tool for the diagnosis of acromegaly, a rare and underdiagnosed disease. Clin. Endocrinol. (Oxf). 84(3), 380–385 (2016).
Katznelson, L. et al. Acromegaly: An endocrine society clinical practice guideline. J. Clin. Endocrinol. Metab. 99(11), 3933–3951 (2014).
Giustina, A. et al. Multidisciplinary management of acromegaly: A consensus. Rev. Endocr. Metab. Disord. 21(4), 667–678 (2020).
Fleseriu, M. et al. A Pituitary Society update to acromegaly management guidelines. Pituitary 24, 1–13 (2021).
Grottoli, S. et al. ACROSTUDY: The Italian experience. Endocrine 48(1), 334–341 (2015).
Filopanti, M. et al. Growth hormone receptor variants and response to pegvisomant in monotherapy or in combination with somatostatin analogs in acromegalic patients: A multicenter study. J. Clin. Endocrinol. Metab. 97(2), E165–E172 (2012).
Ben-Shlomo, A., Sheppard, M. C., Stephens, J. M., Pulgar, S. & Melmed, S. Clinical, quality of life, and economic value of acromegaly disease control. Pituitary 14(3), 284–294 (2011).
Whittington, M. D., Munoz, K. A., Whalen, J. D., Ribeiro-Oliveira, A. & Campbell, J. D. Economic and clinical burden of comorbidities among patients with acromegaly. Growth Horm. IGF Res. 59, 101389 (2021).
Trifirò, G. et al. The role of European Healthcare Databases for post-marketing drug effectiveness, safety and value evaluation: Where does Italy stand?. Drug Saf. 42(3), 347–363 (2019).
Crisafulli, S. et al. Role of healthcare databases and registries for surveillance of orphan drugs in the real-world setting: The Italian case study. Expert Opin. Drug Saf. 18(6), 497–509 (2019).
Broder, M. S., Chang, E., Cherepanov, D., Neary, M. P. & Ludlam, W. H. Incidence and prevalence of acromegaly in the United States: A claims based analysis. Endocr. Pract. 22(11), 1327–1335 (2016).
Burton, T., Le Nestour, E., Neary, M. & Ludlam, W. H. Incidence and prevalence of acromegaly in a large US health plan database. Pituitary 19(3), 262–267 (2016).
Placzek, H., Xu, Y., Mu, Y., Begelman, S. M. & Fisher, M. Clinical and economic burden of commercially insured patients with acromegaly in the United States: A retrospective analysis. J. Manag. Care Spec. Pharm. 21(12), 1106–1112 (2015).
Youden, W. J. Index for rating diagnostic tests. Cancer 3(1), 32–35 (1950).
Trebble, T. M., Hansi, N., Hydes, T., Smith, M. A. & Baker, M. Process mapping the patient journey: An introduction. BMJ 341, c4078 (2010).
Jane, J. A. Jr. et al. Endoscopic transsphenoidal surgery for acromegaly: Remission using modern criteria, complications, and predictors of outcome. J. Clin. Endocrinol. Metab. 96(9), 2732–2740 (2011).
Abe, T. & Lüdecke, D. K. Recent primary transnasal surgical outcomes associated with intraoperative growth hormone measurement in acromegaly. Clin. Endocrinol. (Oxf). 50(1), 27–35 (1999).
Campbell, P. G. et al. Outcomes after a purely endoscopic transsphenoidal resection of growth hormone-secreting pituitary adenomas. Neurosurg. Focus 29(4), E5 (2010).
Gittoes, N. J., Sheppard, M. C., Johnson, A. P. & Stewart, P. M. Outcome of surgery for acromegaly—The experience of a dedicated pituitary surgeon. QJM 92(12), 741–745 (1999).
Giustina, A. et al. Criteria for cure of acromegaly: A consensus statement. J. Clin. Endocrinol. Metab. 85(2), 526–529 (2000).
Funding
This study was conducted in the context of the “INSPIRE” Progetti di Ricerca di Interesse Nazionale (PRIN) project, which received a grant from the Italian Ministry of Education, University and Research (2017N8CK4K).
Author information
Authors and Affiliations
Contributions
S.C.: writing the original draft and interpretation of data. A.F., L.L., V.I.: data analysis, visualization and interpretation of data. D.G., A.C., M.C.D.M., M.R., J.S., F.B.A.: revising the manuscript critically for important intellectual content. G.T.: conception and design of the study, interpretation of data and supervision. All authors contributed to and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
G.T. has served in the last three years on advisory boards/seminars funded by SANOFI, Eli Lilly, AstraZeneca, Abbvie, Servier, Mylan, Gilead, Amgen; he was the scientific director of a Master program on pharmacovigilance, pharmacoepidemiology and real-world evidence which has received non-conditional grant from various pharmaceutical companies; he coordinated a pharmacoepidemiology team at the University of Messina until October 2020, which has received funding for conducting observational studies from various pharmaceutical companies (Boehringer Ingelheim, Daichii Sankyo, PTC Pharmaceuticals). He is also scientific coordinator of the academic spin-off "INSPIRE srl" which has received funding for conducting observational studies from contract research organizations (RTI Health Solutions, Pharmo Institute N.V.). None of these listed activities are related to the topic of the manuscript. The other authors have no other relevant affiliations or financial involvement with any organization or entity with a financial interest in or financial conflict with the subject matter or materials discussed in the manuscript apart from those disclosed.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Crisafulli, S., Fontana, A., L’Abbate, L. et al. Development and testing of diagnostic algorithms to identify patients with acromegaly in Southern Italian claims databases. Sci Rep 12, 15843 (2022). https://doi.org/10.1038/s41598-022-20295-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-022-20295-4
This article is cited by
-
Machine learning-based algorithms applied to drug prescriptions and other healthcare services in the Sicilian claims database to identify acromegaly as a model for the earlier diagnosis of rare diseases
Scientific Reports (2024)
-
Establishing a valid cohort of patients with acromegaly by combining the National Patient Register with the Swedish Pituitary Register
Journal of Endocrinological Investigation (2023)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
