Download presentation
Presentation is loading. Please wait.

1
Neural networks

2
Neural networks Neural networks are made up of many artificial neurons. Each input into the neuron has its own weight associated with it illustrated by the red circle. A weight is simply a floating point number and it's these we adjust when we eventually come to train the network.

3
Neural networks A neuron can have any number of inputs from one to n, where n is the total number of inputs. The inputs may be represented therefore as x1, x2, x3… xn. And the corresponding weights for the inputs as w1, w2, w3… wn. Output a = x1w1+x2w2+x3w3... +xnwn

4
How do we actually use an artificial neuron?
feedforward network: The neurons in each layer feed their output forward to the next layer until we get the final output from the neural network. There can be any number of hidden layers within a feedforward network. The number of neurons can be completely arbitrary.

5
Neural Networks by an Example
let's design a neural network that will detect the number '4'. Given a panel made up of a grid of lights which can be either on or off, we want our neural net to let us know whenever it thinks it sees the character '4'. The panel is eight cells square and looks like this: the neural net will have 64 inputs, each one representing a particular cell in the panel and a hidden layer consisting of a number of neurons (more on this later) all feeding their output into just one neuron in the output layer
 all feeding their output into just one neuron in the output layer.")
6
Neural Networks by an Example
initialize the neural net with random weights feed it a series of inputs which represent, in this example, the different panel configurations For each configuration we check to see what its output is and adjust the weights accordingly so that whenever it sees something looking like a number 4 it outputs a 1 and for everything else it outputs a zero. More:

7
Multi-Layer Perceptron (MLP)
")
8
However, we will concentrate on nets with units arranged in layers
x1 xn We will introduce the MLP and the backpropagation algorithm which is used to train it MLP used to describe any general feedforward (no recurrent connections) network However, we will concentrate on nets with units arranged in layers
 network. However, we will concentrate on nets with units arranged in layers.")
9
x1 xn NB different books refer to the above as either 4 layer (no. of layers of neurons) or 3 layer (no. of layers of adaptive weights). We will follow the latter convention 1st question: what do the extra layers gain you? Start with looking at what a single layer can’t do
 or 3 layer (no. of layers of adaptive weights). We will follow the latter convention. 1st question: what do the extra layers gain you Start with looking at what a single layer can’t do.")
10
Perceptron Learning Theorem
Recap: A perceptron (threshold unit) can learn anything that it can represent (i.e. anything separable with a hyperplane)
 can learn anything that it can represent (i.e. anything separable with a hyperplane)")
11
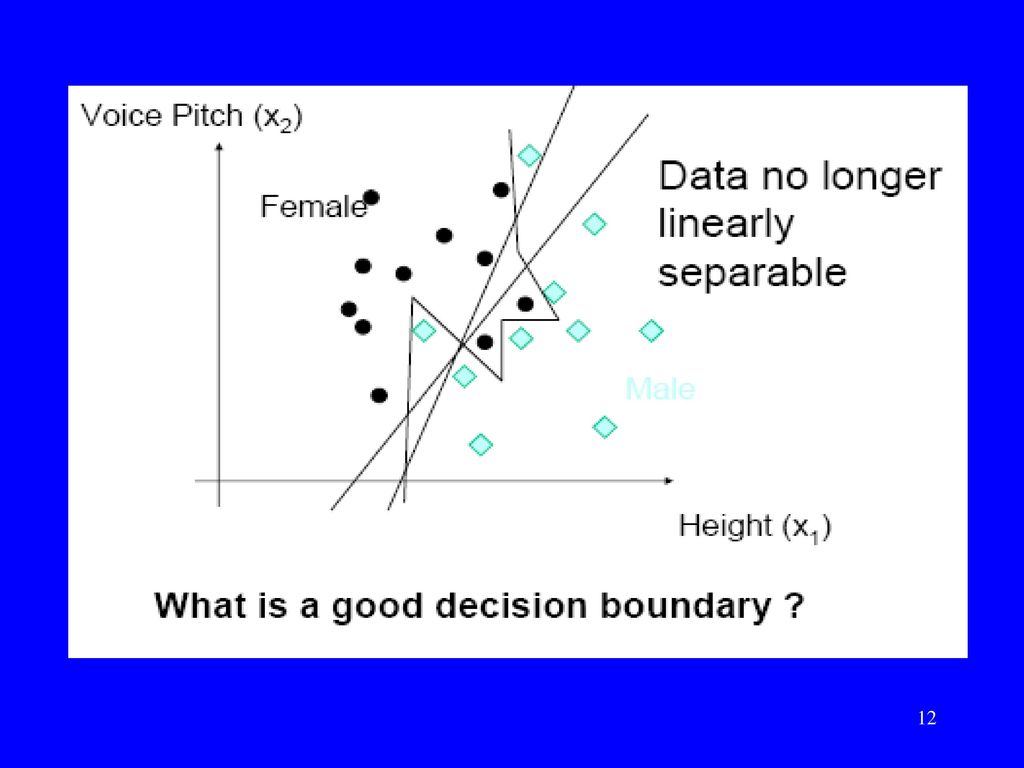
The Exclusive OR problem
A Perceptron cannot represent Exclusive OR since it is not linearly separable.

13
Minsky & Papert (1969) offered solution to XOR problem by
combining perceptron unit responses using a second layer of Units. Piecewise linear classification using an MLP with threshold (perceptron) units +1 1 3 2 +1
 units")
14
xn x1 x2 Input Output Three-layer networks Hidden layers

15
Properties of architecture
No connections within a layer Each unit is a perceptron

16
Properties of architecture
No connections within a layer No direct connections between input and output layers Each unit is a perceptron

17
Properties of architecture
No connections within a layer No direct connections between input and output layers Fully connected between layers Each unit is a perceptron

18
Properties of architecture
No connections within a layer No direct connections between input and output layers Fully connected between layers Often more than 3 layers Number of output units need not equal number of input units Number of hidden units per layer can be more or less than input or output units Each unit is a perceptron Often include bias as an extra weight

19
What do each of the layers do?
3rd layer can generate arbitrarily complex boundaries 1st layer draws linear boundaries 2nd layer combines the boundaries

20
Backpropagation learning algorithm ‘BP’
Solution to credit assignment problem in MLP. Rumelhart, Hinton and Williams (1986) (though actually invented earlier in a PhD thesis relating to economics) BP has two phases: Forward pass phase: computes ‘functional signal’, feed forward propagation of input pattern signals through network Backward pass phase: computes ‘error signal’, propagates the error backwards through network starting at output units (where the error is the difference between actual and desired output values)
 (though actually invented earlier in a PhD thesis relating to economics) BP has two phases: Forward pass phase: computes ‘functional signal’, feed forward. propagation of input pattern signals through network. Backward pass phase: computes ‘error signal’, propagates. the error backwards through network starting at output units. (where the error is the difference between actual and desired. output values)")
21
Conceptually: Forward Activity - Backward Error

22
Forward Propagation of Activity
Step 1: Initialise weights at random, choose a learning rate η Until network is trained: For each training example i.e. input pattern and target output(s): Step 2: Do forward pass through net (with fixed weights) to produce output(s) i.e., in Forward Direction, layer by layer: Inputs applied Multiplied by weights Summed ‘Squashed’ by sigmoid activation function Output passed to each neuron in next layer Repeat above until network output(s) produced
: Step 2: Do forward pass through net (with fixed weights) to produce output(s) i.e., in Forward Direction, layer by layer: Inputs applied. Multiplied by weights. Summed. ‘Squashed’ by sigmoid activation function. Output passed to each neuron in next layer. Repeat above until network output(s) produced.")
23
Step 3. Back-propagation of error

24
‘Back-prop’ algorithm summary (with Maths!) (Not Examinable)
 (Not Examinable)")
25
‘Back-prop’ algorithm summary (with NO Maths!)
")
26
MLP/BP: A worked example

27
Worked example: Forward Pass

28
Worked example: Forward Pass

29
Worked example: Backward Pass

30
Worked example: Update Weights Using Generalized Delta Rule (BP)
")
31
Similarly for the all weights wij:

32
Verification that it works

33
Training This was a single iteration of back-prop
Training requires many iterations with many training examples or epochs (one epoch is entire presentation of complete training set) It can be slow ! Note that computation in MLP is local (with respect to each neuron) Parallel computation implementation is also possible
 It can be slow ! Note that computation in MLP is local (with respect to each neuron) Parallel computation implementation is also possible.")
34
Training and testing data
How many examples ? The more the merrier ! Disjoint training and testing data sets learn from training data but evaluate performance (generalization ability) on unseen test data Aim: minimize error on test data
 on unseen test data. Aim: minimize error on test data.")
35
Binary Logic Unit in an example
MultiLayer Perceptron Learning Algorithm

Similar presentations
>")



>")






 Course website: The back-propagation algorithm Following Hertz chapter 6.>")
>")





. Output Y is 1 if at least two of the three inputs are equal to 1.>")
