Estos días se ha paseado por mi cuenta de Twitter la idea de la aleatoriedad. En general, podemos asumir que el azar se encuentra en la naturaleza. Ahora bien… ¿es posible «generar» el azar por nuestra cuenta? Veámoslo a continuación.
El azar es un fenómeno que ha llamado nuestra atención desde siempre, así como nuestro afán por reproducirlo. Ya hace miles de años se utilizaban dispositivos, como dados o monedas parecidos a los que se muestran en las imágenes, para generar procesos aleatorios en todo aquello que se necesitase (juegos, selecciones…)


¡Más despacio, por favor! «Aleatorio» exactamente, ¿qué significa?
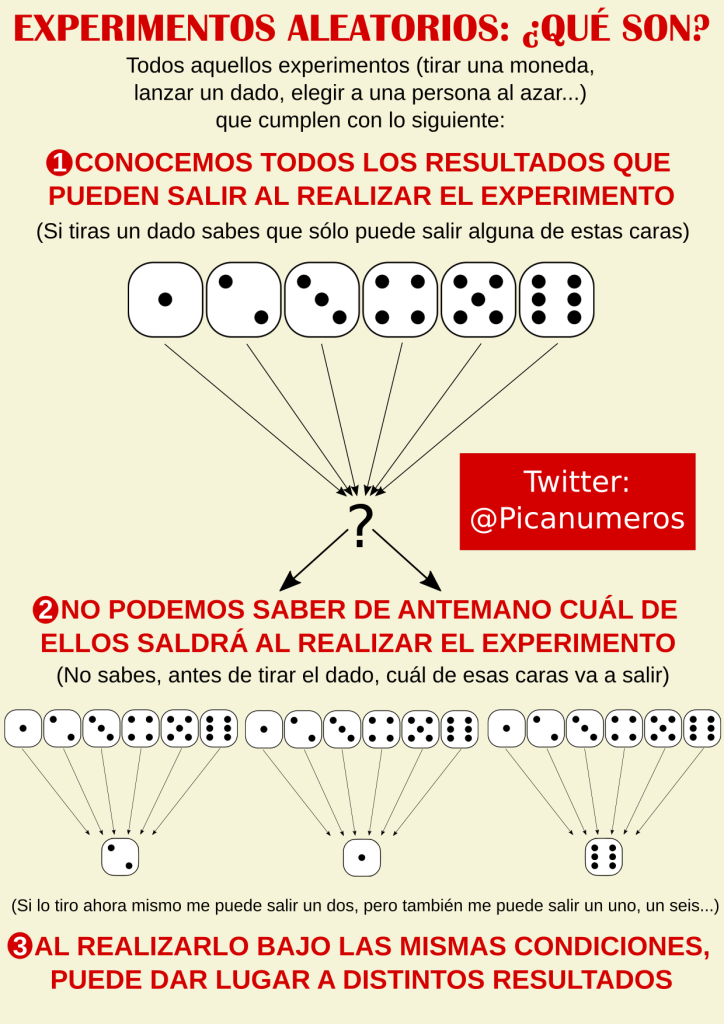
Un experimento aleatorio es todo aquel en el que:
1. Se conocen todos los resultados posibles…
2. …pero no se sabe, ANTES de hacerlo, cuál de ellos saldrá
3. Y repetido bajo mismas condiciones puede dar diferentes resultados
Cosas que NO son necesarias para la aleatoriedad:
– Desconocer las probabilidades de cada resultado. No por saber que la prob. de cara es 50% sabré de qué lado cae la moneda.
– Que todas las probabilidades sean iguales. Cuando tiras un dado, tienes mayor probabilidad de que te salga un número menor que 5, pero eso no quiere decir que sepas cuál va a salir.
Y diréis… ¿Y si yo me pongo a analizar la física de un dado para determinar el resultado?
Pues esto fue lo que descubrieron Persi Diaconis y colegas, pero para las monedas: tirándolas de determinada forma puedes hacer que siempre (o mejor dicho, con probabilidad 1) salga lo que quieras: https://statweb.stanford.edu/~susan/papers/headswithJ.pdf
Esto nos lleva a LA CUESTIÓN:
¿aleatorio es lo que no se sabe porque no puede saberse…
…o porque aún no lo conocemos?
La respuesta no es sencilla, pero me gusta la definición informal de Batanero (2001): el azar es el patrón que explica los fenómenos sin causa o no predecibles.
Esta definición de azar nos puede servir para el día a día en general, y los citados experimentos en particular (tirar una moneda normalmente sí será un experimento aleatorio, basándonos en el paper de Diaconis anteriormente citado), pero no es la opción más rápida para aplicaciones «serias» de la aleatoriedad en la estadística. Así que para solucionar estos problemas, surgieron a principios del S·XX lo que conocemos como tablas de números aleatorios. Y son… pues eso. Tablas con un porrón de dígitos (reunidos mediante procedimientos aleatorios) que podemos ir utilizando secuencialmente según necesidades.

Desde la primera tabla (Tippett, 1927), surgieron varias con longitudes de hasta 100.000 dígitos, pero seguía sin ser suficiente. Los ordenadores, que estaban en su tierna infancia, permitían hacer muestreos aleatorios para los que las tablas se quedaban cortas. En estas surgió el proyecto RAND, que a partir de datos de pulsos electrónicos permitió la obtención masiva de dígitos aleatorios. El fruto fue el libro del MILLÓN de dígitos, publicado en 1955. En él, cada dígito era como una caja de bombones: ¡nunca sabías cuál te iba a tocar!

Pero adivinad qué: esto tampoco era suficiente. Por buenas que fueran estas tablas de números aleatorios, su uso en computadoras resultaba ineficiente y se optó por buscar métodos que pudieran generar esta aleatoriedad.
Y así llegamos a LOS NÚMEROS PSEUDOALEATORIOS.
Los números pseudoaleatorios son aquellos generados por fórmulas como las que adjunto aquí abajo, de tal manera que tú le das un número cualquiera (llamado semilla) y a partir de ahí te genera una secuencia de números hasta el infinito.

¿Son aleatorios estos números? No estrictamente, pero los números generados en la práctica se asemejan a secuencias aleatorias. Son infinitos números, entre 0 y 1, que siempre serán los mismos para una misma semilla, pero que no conoces con exactitud antes de decidirte por alguna. Y presentan múltiples ventajas:
- Permiten reproducir un experimento en diferentes momentos y/o circunstancias (ya que al usar una misma semilla, saldrán los mismos números).
- No hace falta almacenarlos (como sí ocurría con las tablas).
- Los puedes generar a gran velocidad, y todos los que quieras.
¿Y de qué sirve tener estos números? ¡Yo lo que quiero es simular una cara o una cruz! Bien: podemos transformar estos números entre 0 y 1 para lo que queramos, utilizando métodos como el de Monte Carlo. Por ejemplo: si sale menor que 0.5, decimos «cara». Si no, «cruz».
¿Puede comprobarse si un generador de números pseudoaleatorios es bueno o no? Por supuesto que puede. El principal método es mirar si tiene ciclos, es decir, si tras una serie de pasadas, se está generando una sucesión que ya hemos visto antes. Lo suyo es que aparezcan tan tarde que ni nos enteremos.
También podemos pasarlos por los tests de hipótesis sobre uniformidad o autocorrelación, que normalmente usamos para datos reales, para ver si cuadran con esa hipótesis o no. Pero son palabras mayores… así que lo podemos dejar aquí.
Si (y sólo si) te ha gustado esta entrada, me ayudaría un montón que me siguieses en mi cuenta de Twitter, donde podrás leer contenido similar a este. Y si te quedan dudas sobre algo planteado aquí, puedes enviarme una pregunta al Curious.
Referencias:
- Batanero, C. (2001) Didáctica de la estadística. Universidad de Granada.
- L’Écuyer, P. (2017) History of uniform random number generation. WSC 2017. Las Vegas, EEUU (https://hal.inria.fr/hal-01561551/document)
- Bennett, D. J. (1999) Randomness. Harvard University Press.

_with_faces_inscribed_with_Greek_letters_MET_10.130.1158_001.jpg){kind=link}
{kind=link}